Dans cet article, nous nous intéressons aux moyennes d’échantillons. Nous devons donc débuter en décrivant la spécificité de la distribution d’échantillonnage de la moyenne. Pour ce faire, nous proposons une démonstration par le biais de R.
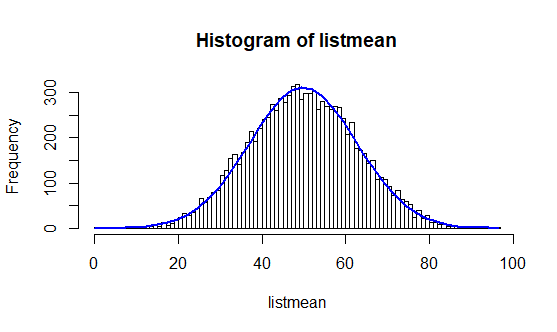
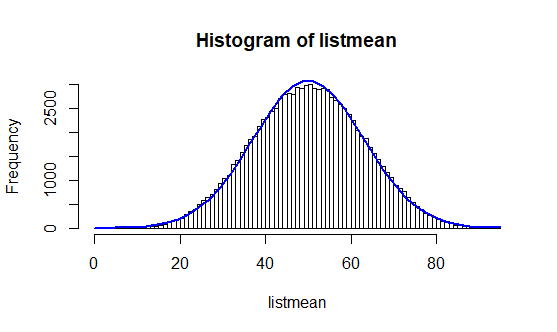
Le théorème central limite résume, à lui seul, les spécificités de ce type de distribution. Ce théorème stipule qu’une somme de variables aléatoires identiques et indépendantes tendra le plus souvent vers une variable aléatoire gaussienne.
Démonstration !
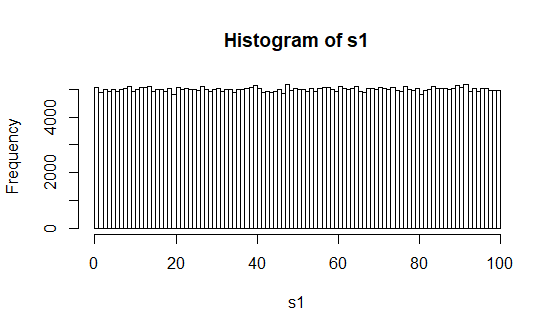
Nous commençons par générer une suite de 500 000 nombres aléatoires.
# Ici 500 000 nombres compris entre 0 et 100 sont générés de façon aléatoire avec remise. s1 = runif(500000, min=0, max=100)
# Plot : On observe la forme de la distribution h = hist(s1, freq=T, breaks=100)
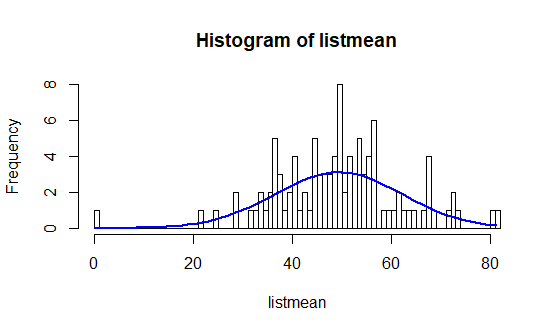
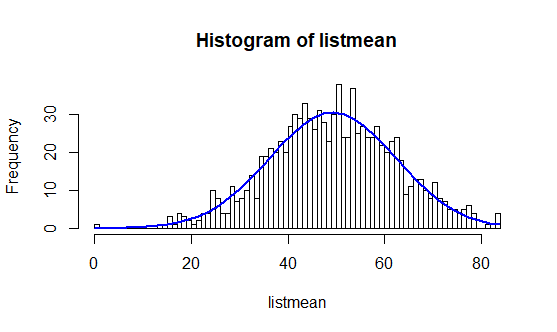
Parmi ces 500 000 nombres, nous tirons au sort plusieurs échantillons d’un effectif égal à 5 (n = 5) et nous calculons leurs moyennes. Puis nous faisons varier le nombre d’échantillons et observons les différentes distributions.
# Boucle permettant de tirer au sort des groupes de 5 nombres parmi ceux générés plus haut + calcule de leurs moyennes count <- 0 consigne_by_sample = 5 nb_of_draw = 100 listmean = 0
Ainsi, nous pouvons voir se réaliser la prédiction du théorème central limite au fur et à mesure des tirages. En effet, plus les tirages sont nombreux, plus la courbe a la forme d’une cloche.
Comparaison de moyennes
Il ne s’agit pas ici de comparer une observation à une distribution d’observations mais une moyenne à une distribution de moyennes (la distribution d’échantillonnage de la moyenne) (Howell, 2008).
L’utilité du t-test vient du fait que, dans une grande majorité des cas, nous ne connaissons pas la variance de la population à laquelle est appliqué le test d’hypothèse. Dans le cas contraire, il aurait été possible de calculer le score z (z = (moyenne observée – moyenne de la distribution d’échantillonnage) / erreur standard de la moyenne) afin d’exprimer (en unité : erreur standard de la moyenne) la distance entre la moyenne observée et la moyenne de la distribution d’échantillonnage, puis, de lire dans le tableau (loi normale), la probabilité d’obtenir une telle valeur. Si la variance n’est pas connue, alors nous ne calculons plus un score z mais un score t qui sera évalué par le biais d’une autre table (t). Le score t est, en fait, une transformation du score z permettant une meilleure symétrie de la distribution de la variance des distributions d’échantillonnage. Nous ne rentrerons pas davantage dans les détails.
Plusieurs applications du test de student sont possibles :
Ce test permet de comparer une moyenne à une valeur théorique par le biais du test de student à échantillon unique (one sample t-test).
Il permet également de comparer deux moyennes extraites de deux échantillons indépendants (test de student non apparié).
Enfin, le test de student apparié, est utilisé pour comparer les moyennes de deux séries appariés. Par exemple, lorsque l’on mesure un temps de réaction X chez un même sujet avant et après un événement Y.
Test de student à échantillon unique (one sample t-test)
Le one-sample t-test permet de comparer une moyenne observée à une moyenne théorique.
Prenons un exemple.
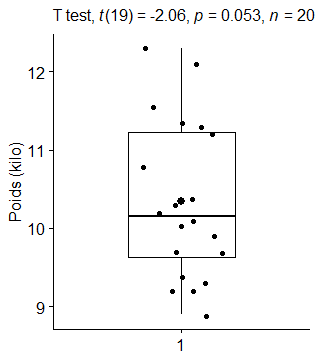
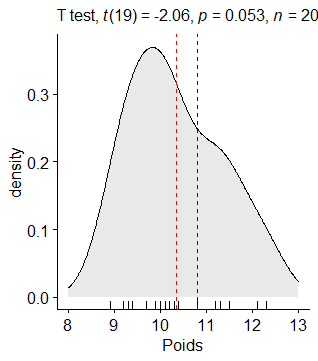
Un groupe de chercheurs souhaite développer une alimentation spécifique pour les labradors. Cette race de chiens développe fréquemment de l’arthrose à l’âge adulte. Les chercheurs ont mis au point une alimentation permettant d’éviter cette pathologie. Toutefois, il se demande si cette alimentation n’engendrerait pas un surpoids à l’âge adulte. Pour tester la nouvelle alimentation, les chercheurs ont recruté 20 labradors femelles de 3 mois dont les maîtres se sont portés volontaires pour participer à l’étude. Ayant fait l’hypothèse d’un impact sur la poids, les chercheurs veulent s’assurer que les chiots recrutés sont bien représentatifs, en termes de poids, de la population générale. Ils savent qu’en moyenne le poids d’un labrador femelle de 3 mois est de 10.8 kilos.
Copier/coller les données ci-dessous dans un script R
#### Charger les packages suivants library(tidyverse) library(ggpubr) library(rstatix)
Hypothèse nulle (H0) : La moyenne de poids des femelles labradors de l’échantillon ne diffère pas de la moyenne de la population générale.
Le résultat obtenu est le suivant :
.y.
group1
group2
n
statistic
df
p
Poids
1
null model
20
-2.06
19
0.0532
groupe 1, groupe 2 = aux groupes comparés. Ici, le groupe 2 est nul puisque nous ne comparons pas deux moyennes mais essayons de déterminer si l’échantillon a un poids moyen significativement différent de la population générale. n = effectif statistic = valeur de la statistique t df = degré de liberté = n-1 p = p-value
Taille d’effet = – 0.461 (small)
Conclusion : la p-value est inférieure à .05. Nous ne pouvons donc pas rejeter H0. Ainsi, nous pouvons conclure que le poids moyen de l’échantillon est significativement différent de celui de la population générale. Les chercheurs peuvent donc utiliser cet échantillon pour le test.
Visualisation :
Copier/coller les données ci-dessous dans un script R
Le Kappa de Cohen (Cohen, 1960) est utilisé pour mesurer la force de l’accord entre deux évaluateurs ou deux méthodes de classification (dans le cas du machine learning par exemple).
Contrairement à une mesure classique de concordance par ratio (pourcentage), le Kappa de Cohen permet de comparer les résultats obtenus aux concordances qu’il serait possible d’observer si celles-ci étaient dues à des jugements hasardeux.
Il existe plusieurs Kappa. Le Kappa pondéré utilisé pour les variables ordinales, le Kappa de Light qui est une moyenne de tous les Kappa de Cohen lorsqu’il y a plus de deux variables catégorielles et le Kappa de Fleiss étant une adaptation du Kappa de Cohen lorsque les évaluateurs sont supérieurs à deux.
Kappa pour deux évaluateurs
Exemple :
Deux paléontologues ont pour mission d’identifier des ossements. Ils ont devant eux 8 jeux d’ossements et doivent indiquer si oui ou non ces ossements appartiennent à l’époque du Néandertal. Les résultats obtenus sont les suivants :
Jeux d’ossements
Paléontologue 1
Paléontologue 2
1
Oui
Oui
2
Oui
Oui
3
Non
Non
4
Oui
Non
5
Non
Oui
6
Non
Non
7
Oui
Non
8
Non
Non
Nous posons l’hypothèse nulle : La concordance entre les évaluateurs est due au hasard.
Copiez le script suivant dans R : (prérequis : package irr)
#install.packages(« irr ») library(irr)
# Création des listes de réponses eval1 = c(‘oui’,’oui’,’non’,’oui’,’non’,’non’,’oui’,’non’) eval2 = c(‘oui’,’oui’,’non’,’non’,’oui’,’non’,’non’,’non’)
# Création du tableau tab3 = cbind(eval1, eval2)
# Description (calcul du ratio d’accords) agree(tab3[,1:2]) #,1:2 signifie que l’on sélectionne les deux colonnes
# Test kappa2(tab3[,1:2],weight = « unweighted »)
Les résultats obtenus sont les suivants :
%-agree = 62.5 : ratio d’accords Subjects = 8 : nombre de sujets évalués Raters = 2 : nombre d’évaluateurs Kappa = 0.25 : coefficient de Kappa z = 0.73 : valeur du test statistique p-value = 0.465 : la p-value du test ou la probabilité de rejeter l’hypothèse nulle alors qu’elle est vraie.
Conclusion :
Une lecture du tableau ci-dessous (Landis et Koch, 1977) permet de qualifier la force du lien existant :
κ
Force de l’accord
< 0
Désaccord
0.0 – 0.20
Accord très faible
0.21– 0.40
Accord faible
0.41– 0.60
Accord modéré
0.61– 0.80
Accord fort
0.81– 1.00
Accord presque parfait
Le lien obtenu est faible. En outre, la p-value ne nous permet pas de rejeter l’hypothèse nulle. En d’autres termes, nous pouvons prétendre que la différence observée n’est pas due au hasard.
Kappa pondéré pour deux évaluateurs avec données ordinales
Les paléontologues devaient ensuite évaluer l’état des ossements. Pour cela, il leur fallait attribuer pour chaque jeu d’ossements une note allant de 1 : (mauvais état) à 5 : (excellent état)
Voici les résultats :
Jeux d’ossements
Paléontologue 1
Paléontologue 2
1
2
3
2
1
3
3
4
4
4
3
5
5
1
3
6
1
1
7
2
2
8
3
3
Nous posons l’hypothèse nulle : La concordance entre les évaluateurs est due au hasard.
Copiez le script suivant dans R :
# Création des listes de réponses eval4 = c(2, 1, 4, 3, 1, 1, 2, 3) eval5 = c(3, 3, 4, 5, 3, 1, 2, 3)
# Création du tableau tab5 = cbind(eval4, eval5)
# Description (calcul du ratio d’accords) agree(tab5[,1:2])
# Test kappa2(tab5[,1:2],weight = « equal »)
Résultats :
%-agree = 50 : notons qu’ici, le degré d’accord non corrigé n’est pas un très bon indicateur. En effet, il ne prend en compte que les accords stricts sur une échelle à plusieurs niveaux. Subjects = 8 Raters = 2 Kappa = 0.378 z = 2.09 p-value = 0.0366
Conclusion :
Une lecture du tableau (Landis et Koch, 1977) nous enseigne que le lien inter-juges peut être considéré comme faible. Toutefois, cette fois-ci, l’hypothèse nulle peut être rejetée au seuil de .05. Le lien établi, ne semble pas être le fruit du hasard. Nous pouvons donc prétendre que les chercheurs sont d’accord entre eux.
Kappa de Light’s : évaluateurs multiples de plusieurs variables catégorielles
Les premiers résultats de l’évaluation des ossements concernant leur époque d’appartenance n’ayant pas été probants, 3 collègues se joignent à nos 2 paléontologues.
Voici les évaluations totales :
Jeux d’ossements
Palé.1
Palé.2
Palé.3
Palé.4
Palé.5
1
Oui
Oui
Oui
Oui
Oui
2
Oui
Oui
Oui
Non
Oui
3
Non
Non
Oui
Non
Non
4
Oui
Non
Oui
Oui
Oui
5
Non
Oui
Oui
Non
Oui
6
Non
Non
Non
Non
Non
7
Oui
Non
Oui
Non
Oui
8
Non
Non
Non
Oui
Non
Nous posons l’hypothèse nulle : La concordance entre les évaluateurs est due au hasard.
Copiez le script suivant dans R :
# Création des listes de réponses eval10 = c(‘oui’,’oui’,’non’,’oui’,’non’,’non’,’oui’,’non’) eval11 = c(‘oui’,’oui’,’non’,’non’,’oui’,’non’,’non’,’non’) eval12 = c(‘oui’,’oui’,’oui’,’oui’,’oui’,’non’,’oui’,’non’) eval13 = c(‘oui’,’non’,’non’,’oui’,’non’,’non’,’non’,’oui’) eval14 = c(‘oui’,’oui’,’non’,’oui’,’oui’,’non’,’oui’,’non’)
# Création du tableau tab10 = cbind(eval10, eval11, eval12, eval13, eval14)
# Description (calcul du ratio d’accords) agree(tab10[,1:5])
# Test kappam.light(tab10[,1:5])
Résultats :
%-agree = 25 : notons qu’ici encore, le degré d’accord non corrigé n’est pas un bon indicateur. En effet, il ne prend en compte que les accords stricts sur une échelle à plusieurs niveaux. Subjects = 8 Raters = 5 Kappa = 0.321 z = 0.0976 p-value = 0.922
Le kappa de Light’s est utilisé ici. Il retourne le kappa moyen de Cohen lors de l’évaluation de variables catégorielles par plus de 2 évaluateurs.
Conclusion : Une lecture du tableau (Landis et Koch, 1977) nous enseigne que le lien inter-juges peut être considéré comme faible. Toutefois, l’hypothèse nulle ne peut être rejetée au seuil de .05. Nous ne pouvons prétendre que la différence observée n’est pas due au hasard.
Kappa de Fleiss évaluateurs multiples de plusieurs variables non-catégorielles
Profitant de la présence de leurs collègues, nos deux premiers paléontologues proposent de réitérer l’évaluation quant à l’état des ossements afin de donner davantage de poids à leur première expertise. Les résultats obtenus sont les suivants :
Jeux d’ossements
Palé.1
Palé.2
Palé.3
Palé.4
Palé.5
1
2
3
2
3
3
2
1
3
2
3
2
3
4
4
4
4
4
4
3
5
4
4
4
5
1
3
2
1
1
6
1
1
1
1
1
7
2
2
2
2
2
8
3
3
3
3
3
Nous posons l’hypothèse nulle : La concordance entre les évaluateurs est due au hasard. Copiez le script suivant dans R :
# Création du tableau tab1 = cbind(eval1, eval2, eval3, eval4, eval5)
# Description (calcul du ratio d’accords) agree(tab1[,1:5])
# Test kappam.fleiss(tab1[,1:5])
Résultats :
%-agree = 50 : notons qu’ici encore, le degré d’accord non corrigé n’est pas un bon indicateur. En effet, il ne prend en compte que les accords stricts sur une échelle à plusieurs niveaux.
Une lecture du tableau (Landis et Koch, 1977) nous enseigne que le lien inter-juge peut être considéré comme modéré. L’hypothèse nulle est rejetée au seuil de .05. Nous pouvons prétendre que la différence observée n’est pas due au hasard.
L’effet de halo est également appelé « effet de notoriété » ou « effet de contamination ». C’est un biais cognitif. Il constitue la tendance à généraliser une caractéristique saillante d’un individu à l’ensemble de sa personnalité.
Non mais halo quoi !
Nous vous présentons ici une vidéo qui est la toute première d’une série intitulée « crétin de cerveau » du chercheur et vulgarisateur scientifique David Louapre, créateur de la chaîne « science étonnante ».
Dans une série intitulée « crétin de cerveau » le chercheur et vulgarisateur scientifique David Louapre, se donne pour mission d’expliquer les différents biais cognitifs. Selon lui, ceux-ci engendrent des erreurs de jugement. et nous poussent à nous laisser influencer.
David Louapre focalise son propos majoritairement sur l’apparence physique (taille, attractivité). En effet, certaines études en démontrent son impact sur :
le vote des électeurs;
la rémunération des salariés,
l’évaluation de la personnalité ou encore
l’attribution de la culpabilité lors d’un procès.
Ainsi, tous ces comportements d’importance ont pour point commun l’influence de l’apparence physique. Sidérant n’est-il pas ?
Pour aller plus loin, vous pouvez lire le billet de blog accompagnant la vidéo dans lequel l’auteur critique certains points méthodologiques.
Quelles implications identitaires ?
L’effet de halo, peut donc générer des effets négatifs en terme d’auto-perception. De faibles indices perçues d’un individu généralisés à l’ensemble de sa personnalité vont le conduire progressivement à intérioriser ce stéréotype négatif.
A l’issue d’expériences répétées de ce type, l’individu pourra s’identifier à ce stéréotype (peu importe son fondement réel ou non). Ce mécanisme est d’ailleurs très bien décrit par Georges Chadron dans un article de synthèse. Pour contrer ce phénomène, la recherche indique que la conscience du phénomène constitue la première étape.
A l’échelle sociétale, ce mécanisme de halo peut engendrer des effets considérables. Il se produit lorsque la connaissance de l’identité d’un groupe donné est partielle ou inexistante et qu’un membre dudit groupe fait irruption dans le paysage social d’un autre groupe. L’apparition soudaine de cet individu porte à généraliser ses caractéristiques à l’ensemble de la population qu’il est censé représenter.
La simplification devient problématique dès lors que l’individu « modèle » n’est absolument pas représentatif du groupe qu’il incarne. Cet effet négatif est par ailleurs illustré par le cas Borat. C’est le nom d’un docufilm parodique, mettant en scène un prétendu Kazakh aux USA. Le sarcasme caractéristique du ton du film a eu des incidences sur la scène diplomatique notamment avec le Kazakhstan. La critique du modèle dominant états-unien n’a pas été perçue de la même manière en fonction des identités culturelles; Cette perception a ainsi conduit certains pays comme la Russie à en censurer une partie du contenu.
Quand on vous dit que la première impression compte, c’est en partie corroborée par l’effet de halo. La première impression a tendance à contaminer l’entièreté de la perception de la personne et réduire la prise en compte d’évènements qui viendraient contredire ces premiers indices.
Vous êtes-vous déjà demandé ce qu’une faute de frappe dans une feuille Excel pouvait engendrer ?
Dans cette vidéo de la chaîne ScienceEtonnante, David Louapre explique comment une erreur de calcul (dans le meilleur de cas) pourrait être à l’origine de recommandations mondiales en matière d’austérité.
Cette histoire nous permet de mettre en lumière l’importance du respect de la démarche scientifique et notamment de l’évaluation par les pairs.
Retrouvez les données ainsi que le code utilisé dans la vidéo sur cette page.
Le chi² va nous permettre de traiter des données de type catégorielles c’est à dire des données relatives à la fréquence d’une observation. Par exemple, si nous observons la répartition des membres d’un échantillon dans différentes catégories socio-professionnelles, ce test nous permettra de déterminer si cette répartition est différente de celle qu’on aurait pu observer dans l’ensemble de la population dont est issu l’échantillon.
Le Chi² de conformité
Ce test permet de comparer un effectif à une valeur théorique attendue.
Prenons un exemple : On sait que 5% de la population française possède des cheveux roux. On se demande si, du fait de sa proximité avec le Royaume-Uni, le département du Pas-de-Calais est peuplé davantage de personnes rousses que ce qui pourrait être attendu d’après les données connues au niveau national (effectif théorique attendu : 5% de personnes rousses). On tire au sort 10 000 individus dans l’ensemble du département du Pas-de-Calais. Sur cet échantillon, on dénombre 567 individus roux.
Nous pouvons traduire cet énoncé sous la forme du tableau suivant :
Couleur de cheveux
Echantillon
Proportions de l’échantillon
Résultats attendus
Proportions théoriques
Roux
567
5.67% (0.0567)
500
5% (0.05)
Non-Roux
9 433
94.33% (0.9433)
9 500
95% (0.95)
Totaux
10 000
100% (1)
10 000
100% (1)
Présentation de l’échantillon du département Pas-de-Calais en comparaison aux données nationales. (Données fictives)
Hypothèse nulle (HO) : La proportion de personnes rousses dans le département du Pas-de-Calais n’est pas différente de celle de la France en général.
Copier/coller les lignes de commandes et les commentaires ci-dessous dans un nouveau Script R, puis executer.
Packages nécessaires : packages de base
# Nous créons ici une liste des données obtenues grâce à la fonction « c() » que nous nommons « echantillon »
echantillon<- c(567, 9433)
# Nous créons ici une liste des probabilités théoriques que nous nommons « probabilité »
probabilite<- c(0.05, 0.95)
# Nous lançons le test à l’aide de la fonction « chisq.test() »
chisq.test(echantillon,p=probabilite)
Vous obtenez les résultats suivants :
chi² = 9.4505 => Ce nombre permet habituellement de valider ou de réfuter manuellement l’hypothèse nulle après lecture de la table de chi².
df = 1 => Le df ou ddl est également nécessaire pour la lecture de la table.Il se calcule par le biais de la formule suivante : ddl = (L-1)(C-1). L = nb de colonne et C = nb de colonnes.
p-value = 0.002111 => C’est la probabilité de rejeter l’hypothèse nulle alors qu’elle est vraie.
Conclusion
En nous basant sur un seuil conventionnel d’une valeur de p-value = .05 (appelé aussi α ou Erreur de type I), nous nous devons de rejeter l’hypothèse nulle (.002 < .05). Ce faisant, nous acceptons le risque (0.002111 *100 = 2%) de rejeter cette hypothèse dans le cas où elle se révèlerait être vraie.
Nous pouvons donc dire que le nombre de personnes rousses du département Pas-de-Calais est significativement supérieur à celui de la moyenne nationale.
Le Chi² d’indépendance
Le test du chi² d’indépendance sera utilisé lorsque la question sera de savoir s’il existe ou non une indépendance entre deux critères que nous souhaitons étudier.
Prenons un exemple. Des chercheurs en économie souhaitent savoir si les individus sont davantage enclins à créer une entreprise en fonction du lieu de leur résidence. A la suite d’un sondage national, ils obtiennent les résultats suivants.
Ville
Zone Urbaine
Campagne
Totaux
Entrepreneur
157
222
83
462
Non entrepreneur
567
382
122
1071
Totaux
724
604
205
1533
Répartition des entrepreneurs / non-entrepreneurs par zones territoriales. (Données fictives)
Hypothèsenulle (HO) : Le fait de connaître si un individu vit en ville, en zone urbaine ou en campagne ne nous aide pas à déterminer si celui-ci est entrepreneur ou non.
Copier/coller les lignes de commandes et les commentaires ci-dessous dans un nouveau Script R, puis executer.
Packages nécessaires : packages de base
# Création des listes entrepreneur / non entrepreneur
entrepreneur = c(157, 222, 83)
non_entrepreneur = c(567, 382, 122)
# Création du tableau de contingence (matrice comparative). Notez que ci-dessous, 2 est le nombre de lignes et 3 le nombre de colonnes
tableau = matrix(c(entrepreneur, non_entrepreneur),2,3,byrow=T)
# Réalisation du test khi-deux
chi_test = chisq.test(tableau)
chi_test
Vous obtenez les résultats suivants (pour l’interprétation voir chi² de conformité) :
chi² = 47.56
df = 2
p-value = 4.704e-11
Conclusion
La p-value nous amène à rejeter l’hypothèse nulle. Ainsi nous pouvons en conclure que le fait de savoir si un individu vit en ville, en zone urbaine ou en campagne peut nous donner une indication sur le fait qu’il soit entrepreneur ou non. Évidemment, d’un point de vue théorique, cette donnée seule ne suffit pas mais nous voyons qu’il existe un lien entre ces deux facteurs.
Le chi² d’homogénéité
Ce test est une variante du chi² d’indépendance utilisé pour interroger l’équivalence de la répartition de différents effectifs.
Imaginons le test en laboratoire de 3 traitements (vs placebo) contre un virus mal connu provoquant une pandémie mondiale. Les résultats de ces tests se trouvent dans le tableau suivant.
Baisse de la charge virale 8 jours après premiers symptômes
Pas de baisse de la charge virale 8 jours après premiers symptômes
Totaux
Groupe Placebo
44 (33.5%)
87 (66.5%)
131 (100 %)
Traitement 1
56 (36.1%)
99 (63.9%)
155 (100 %)
Traitement 2
34 (45.3%)
41 (54.7%)
75 (100 %)
Traitement 3
87 (52.7 %)
78 ( 47.3%)
165 (100 %)
Totaux
221
305
526
Répartition des individus en fonction du traitement et de la baisse ou non de la charge virale 8 semaines après les premiers symptômes. (Données fictives)
Hypothèsenulle (HO) : Aucune des conditions est plus performante quant à la diminution de la charge virale 8 jours après les premiers symptômes.
Copier/coller les lignes de commandes et les commentaires ci-dessous dans un nouveau Script R, puis executer.
# Création du tableau de données sous R. Nous utilisons cette fois la fonction rbind.
tableau <- as.table(rbind(c(44, 87), c(56,99), c(34,41), c(87,78)))
dimnames(tableau) <- list(traitement = c("placebo", "T1", "T2", "T3"),
party = c("Baisse","Pas de Baisse"))
tableau # pour afficher le tableau réalisé ci-dessus
# Par la suite, le test du chi² est effectué
chi_test = chisq.test(tableau)
chi_test
Les résultats suivants sont obtenus (pour l’interprétation voir chi² de conformité) :
chi² = 14.134
df = 3
p-value = 0.002729
Nous voyons donc que nous pouvons rejeter l’hypothèse nulle avec, ce faisant, une probabilité de se tromper de 0.002729. Ces résultats indiquent clairement qu’au moins une des conditions engendre des résultats différents des autres. Toutefois, à ce stade, nous ne savons ni dans quel sens, ni de quel protocole il s’agit.
# Nous faisons appel à des sous-fonctions de chisq.test() pour investiguer plus en détail.
# résultats attendus/théoriques si les données sont le fruit du hasard.
chi_test$expected
# résultats observés. Il s'agit en fait du tableau présenté en amont.
chi_test$observed
# différence entre résultats attendus et observés
chi_test$residual
# différence normalisée entre résultats attendus et observés
chi_test$stdres
Ce qui nous intéresse le plus ici est l’analyse des différences entre les données attendues et celles observées (chi.test$residual et chi.test$stdres).
Ci-dessous les résultats bruts du chi.test$stdres (données normalisées) :
traitement Baisse Pas de Baisse placebo -2.2550929 2.2550929 T1 -1.7678473 1.7678473 T2 0.6287349 -0.6287349 T3 3.3650698 -3.3650698
Ces résultats nous permettent d’observer que les plus grandes différences se situent au niveau des traitements placebo et T3. Toutefois, à ce niveau de l’étude nous ne pouvons pas dire si ces différences sont significatives d’un point de vue statistique. Nous pourrions alors faire des comparaisons deux à deux afin de conclure sur une significativité des résultats. Cependant, en faisant cela, on augmenterait l’erreur de type 1, à savoir la probabilité de rejeter l’hypothèse nulle alors que celle-ci est vraie. Afin de se prémunir contre l’augmentation de ce risque, la correction de Bonferroni va être utilisée (il existe d’autres corrections de ce type). Ce dernier permettra de majorer le risque réel pour l’ensemble des tests par le niveau de test choisi (classiquement 5%).
# Execution du test de Bonferroni
chisq.posthoc.test(tableau, method = "bonferroni")
Les résultats bruts obtenus sont les suivants :
Dimension Value Baisse Pas de Baisse 1 placebo Residuals -2.2550929 2.2550929 2 placebo p values 0.1930200 0.1930200 3 T1 Residuals -1.7678473 1.7678473 4 T1 p values 0.6166910 0.6166910 5 T2 Residuals 0.6287349 -0.6287349 6 T2 p values 1.0000000 1.0000000 7 T3 Residuals 3.3650698 -3.3650698 8 T3 p values 0.0061220 0.0061220
Conclusion
Nous constatons, à la lecture de ces résultats et du tableau de présentation des données, que seul le traitement 3 peut être considéré comme davantage efficace pour impacter négativement la charge virale 8 jours après l’apparition des premiers symptômes.
Tailles d’effet
S’il est important en sciences de savoir si la relation entre deux variables est statistiquement significative, cela ne nous dit rien sur la force du lien qui unit ces variables. L’importance de ce lien est appelée la taille d’effet. Nous allons voir ici comment la déterminer avec R et dans le cadre du test de chi².
Une première solution consiste à comparer les résultats du tableau de contingence et d’en faire une interprétation en terme de probabilité. Reprenons par exemple notre dernier tableau. Nous souhaitons comparer le traitement 3 et le traitement placebo. Le premier permet une observation de la baisse de la charge virale 8 jours après l’apparition des premiers symptômes dans 52,7 % des cas alors que le second, seulement dans 33,5 % des cas. On peut donc en conclure que le traitement 3 est (0,527/0,335) = 1.57 fois plus efficace pour faire baisser la charge virale 8 jours après l’apparition des premiers symptômes que le placebo. En outre, nous avons déjà déterminé que cette différence était significative. Toutefois, cette nouvelle donnée sera plus parlante auprès de spécialistes habitués à de tels rapports de grandeur qu’auprès de profanes.
Une seconde solution et de faire appel à d’autres mesures permettant de se focaliser davantage sur la corrélation entre les deux variables tels que le coefficient Phi (dans le cas de tables 2*2) ou le V de Cramér (dans le cas de tables supérieures à 2*2). En reprenant l’exemple ci-dessus (Placebo vs Traitement 3), nous allons montrer comment calculer ces deux valeurs avec R et comment en interpréter les résultats.
Packages nécessaires : packages de base + effectsize
# Taille de l'effet en prenant la totalité des données (tables 4*2)
# Utilisation du V de Cramer
chisq_to_cramers_v(14.134, # On entre manuellement la valeur du Chi²
n = sum(tableau), # On demande une lecture de l'effectif total
nrow = nrow(tableau), # On demande une lecture du nb de lignes
ncol = ncol(tableau), # On demande une lecture du nb de colonnes
ci = 0.95, # On précise l'interval de confiance souhaité
adjust = FALSE # On ne demande pas de correction de biais
)
# Les données peuvent également être entrées manuellement.
convert_chisq_to_cramers_v(
14.134,
n = 526,
nrow = 4,
ncol= 2,
ci = 0.95,
adjust = FALSE,
)
Les résultats obtenus sont les suivants :
cramers_v | 95% CI 0.16 | [0.06, 0.24]
Le V de Cramèr est ici égale à 0.16. Plus ce résultat se rapproche de 1 et plus le lien est important. Classiquement, on évalue l’intensité du V de Cramèr en se référant au tableau suivant.
V de Cramèr
Relation entre les deux variables
< 0.10
Relation nulle ou très faible
>= 0.10 et < 0.20
Relation faible
>= 0.20 et < 0.30
Relation moyenne
>= 0.30
Relation forte
Intensité de la relation de deux variable en fonction de la valeur du V de Cramèr.
L’intervalle de confiance signifie que l’on peut avoir une confiance de 95% sur le fait que le V de Cramèr appartienne à l’intervalle [0.06, 0.24].
Conclusion
Il semble donc que le lien observé dans cette étude soit relativement faible et qu’il conviendrait d’être prudent en essayant, par exemple, de le répliquer.
Conditions d’application du chi²
L’indépendance : » il s’agit par exemple de la condition d’application selon laquelle le choix d’une personne entre différentes marques de café n’a pas d’influence sur le choix d’une autre personne » (Howell, 2009).
L’inclusion des non-occurrences : Prenons l’exemple d’une étude dans laquelle les chercheurs tentent de déterminer si le fait d’être pour la peine de mort est lié au fait d’avoir plus ou moins de 50 ans.
Non inclusion des non-occurrences
– 50 ans
+ 50 ans
Total
Pour la peine de mort
168
180
348
Attendu si idépendance
174
174
348
Répartition des individus pour la peine de mort en fonction du fait d’avoir plus ou moins de 50 ans. (Données fictives)
Inclusion des non-occurrences
– 50 ans
+ 50 ans
Total
Pour la peine de mort
168
180
348
Contre la peine de mort
188
178
366
Total
356
358
714
Répartition des individus pour ou contre la peine de mort en fonction du fait d’avoir plus ou moins de 50 ans. (Données fictives)
« Ne pas prendre en compte les non-occurrence (réponses négatives) a pour effet d’invalider le test et de réduires la valeur du chi², ce qui nous conduit à rejeter moins souvent H0 » (Howell, 2009).
L’auteur recommande de toujours s’assurer que le total (N) est égal au nombre de participants inclus dans l’étude afin d’éviter cette erreur.
Dans l’article ci-dessous datant du 27 janvier 2020, rédigé en anglais et publié sur le site behavioralscientist.org, Stephanie Tam écrivaine, chercheuse et productrice indépendante s’interroge sur l’impact de l’immigration sur l’innovation et l’entrepreneuriat aux Etats-Unis.
Les économistes savent depuis longtemps que l’innovation est une des clés de la croissance. L’auteure essaye de comprendre à quel point l’immigration contribue à l’innovation et nous explique comment les chercheurs ont utilisé les bases de données relatives aux brevets (titres de propriété industrielle) pour répondre à cette question. Ces derniers ont pu montrer que les immigrants contribuaient de façon disproportionnée à l’innovation américaine. Plusieurs raisons sont avancées dans l’article. Ainsi, la propension des immigrants à prendre plus de risque est soulignée. Ces derniers ont déjà tous pris un risque en quittant leur pays. En outre, certaines données montrent que les immigrants ont tendance à faire moins d’études que la population autochtone. En revanche, ceux qui en font se sont retrouvés en grande proportion à des niveaux très avancés (ex : Doctorat). Ils seraient aussi plus susceptibles de créer leur propre travail car leur expérience à l’étranger ne serait pas reconnue sur le sol américain. De façon générale, ils n’auraient pas les mêmes opportunités d’emploi que les américains.
Le fait de ne pas avoir été élevé dans la culture américaine leur octroierait des possibilités de penser hors du cadre culturel commun aux individus nés sur le sol américain et ainsi, leur donnerait un avantage certain en terme d’innovation. Ce sont donc des motifs culturels et motivationnels qui sont principalement avancés pour expliquer le phénomène étudié.
Les chercheurs montrent également que, loin de ne faire que s’accaparer une part de l’emploi, les immigrants contribuent très largement à la création de celui-ci.
La disproportion de la contribution des immigrants se retrouve dans plusieurs secteurs. Ainsi, pas loin de la moitié des 500 entreprises les plus riches des Etats-Unis ont été fondées par les immigrants ou leurs enfants. En outre, un peu plus de la moitié des immigrants ayant eu le prix Nobel en chimie, médecine, physique ou économie vivaient sur le sol américain lors de leurs travaux.
Enfin, il est à noter que des études récentes tendent à montrer que les Etats-Unis sont de moins en moins attractifs pour les talents étrangers au détriment d’autres pays tels que le Canada ou le Royaume-Uni. Cela serait dû au durcissement de la politique d’immigration américaine.
Dans l’article que vous trouverez en cliquant sur le lien ci-dessous, Vincent Yzerbyt et Olivier Klein expliquent en quoi le terme de distanciation sociale, utilisé lors de la crise du coronavirus, est à leurs yeux inapproprié. Ce faisant, les auteurs soulignent l’importance du lien social dans la vie quotidienne et plus particulièrement en temps de crise.