#### Charger les packages suivants
library(tidyverse)
library(ggpubr)
library(rstatix)
#### Constitution du data set
Numero_chiots <- c(‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, ’10’, ’11’, ’12’, ’13’, ’14’, ’15’, ’16’, ’17’, ’18’, ’19’, ’20’)
Poids <- c(9.7, 10, 8.9, 11.5, 12.1, 11.3, 9.2, 9.2, 10.1, 12.3, 9.3, 10.8, 11.2,
10.4, 9.7, 10.2, 9.9, 9.4, 10.3, 11.3)
Poids_Labrador <- data.frame(Numero_chiots, Poids)
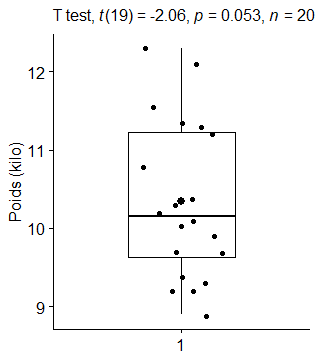
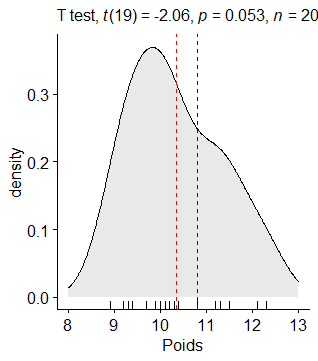
#### Résultat du t-test
result <- Poids_Labrador %>% t_test(Poids ~ 1, mu = 10.8)
result
#### Taille d’effet
Poids_Labrador %>% cohens_d(Poids ~ 1, mu = 10.8)