Centre Interdisciplinaire d'Etude et de Recherche sur les Identités

L’effet de halo est également appelé « effet de notoriété » ou « effet de contamination ». C’est un biais cognitif. Il constitue la tendance à généraliser une caractéristique saillante d’un individu à l’ensemble de sa personnalité.

Nous vous présentons ici une vidéo qui est la toute première d’une série intitulée « crétin de cerveau » du chercheur et vulgarisateur scientifique David Louapre, créateur de la chaîne « science étonnante ».
Dans une série intitulée « crétin de cerveau » le chercheur et vulgarisateur scientifique David Louapre, se donne pour mission d’expliquer les différents biais cognitifs. Selon lui, ceux-ci engendrent des erreurs de jugement. et nous poussent à nous laisser influencer.
David Louapre focalise son propos majoritairement sur l’apparence physique (taille, attractivité). En effet, certaines études en démontrent son impact sur :
Ainsi, tous ces comportements d’importance ont pour point commun l’influence de l’apparence physique. Sidérant n’est-il pas ?
Pour aller plus loin, vous pouvez lire le billet de blog accompagnant la vidéo dans lequel l’auteur critique certains points méthodologiques.
L’effet de halo, peut donc générer des effets négatifs en terme d’auto-perception. De faibles indices perçues d’un individu généralisés à l’ensemble de sa personnalité vont le conduire progressivement à intérioriser ce stéréotype négatif.
A l’issue d’expériences répétées de ce type, l’individu pourra s’identifier à ce stéréotype (peu importe son fondement réel ou non). Ce mécanisme est d’ailleurs très bien décrit par Georges Chadron dans un article de synthèse. Pour contrer ce phénomène, la recherche indique que la conscience du phénomène constitue la première étape.
A l’échelle sociétale, ce mécanisme de halo peut engendrer des effets considérables. Il se produit lorsque la connaissance de l’identité d’un groupe donné est partielle ou inexistante et qu’un membre dudit groupe fait irruption dans le paysage social d’un autre groupe. L’apparition soudaine de cet individu porte à généraliser ses caractéristiques à l’ensemble de la population qu’il est censé représenter.
La simplification devient problématique dès lors que l’individu « modèle » n’est absolument pas représentatif du groupe qu’il incarne. Cet effet négatif est par ailleurs illustré par le cas Borat. C’est le nom d’un docufilm parodique, mettant en scène un prétendu Kazakh aux USA. Le sarcasme caractéristique du ton du film a eu des incidences sur la scène diplomatique notamment avec le Kazakhstan. La critique du modèle dominant états-unien n’a pas été perçue de la même manière en fonction des identités culturelles; Cette perception a ainsi conduit certains pays comme la Russie à en censurer une partie du contenu.
Quand on vous dit que la première impression compte, c’est en partie corroborée par l’effet de halo. La première impression a tendance à contaminer l’entièreté de la perception de la personne et réduire la prise en compte d’évènements qui viendraient contredire ces premiers indices.

L’article a été publié le 28 avril 2020 sur le site de l’Institut Arctique. Ce centre est dédié aux études liées à la sécurité du Cercle polaire arctique. Ses travaux de recherche s’intéressent aux problématiques régionales dans les domaines militaires, économiques, socio-politiques, culturels et environnementaux.
Cette analyse est rédigée par Marc Lanteigne, professeur de Sciences politiques associé à l’Université de Tromsø en Norvège. Il est également l’auteur du blog Over the Circle qui étudie l’actualité géopolitique de la région polaire.
L’auteur aborde le développement de la diplomatie chinoise en Arctique. Il explique notamment les leviers de construction de son identité dans la région. Pointant les enjeux économiques et l’émergence de risques nouveaux, cet article explique comment le Cercle polaire Arctique est devenu une nouvelle zone d’influence de la Chine.
Après un premier refus en 2009, la Chine a intégré en 2013 le Conseil de l’Arctique avec quatre autres pays d’Asie Pacifique (le Japon, l’Inde, Singapour et la Corée du Sud). En dépit d’un manque manifeste en matière d’exploration polaire, ces nouveaux entrants ont proposé des investissements économiques massifs afin de faire avancer la recherche scientifique sur les thématiques arctiques. C’est de cette façon qu’ils ont apporté leur contribution aux réflexions du Conseil. Dès lors, les intérêts chinois pour cette zone n’ont cessé de croître. C’est ainsi qu’est née la diplomatie chinoise de l’Arctique.
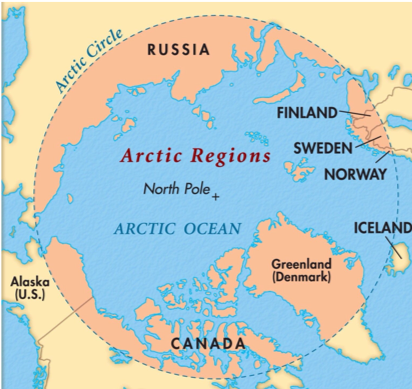
Pour la Chine, le premier enjeu de cette stratégie était de se faire accepter comme un acteur régional légitime. Le développement de l’identité arctique de la Chine a commencé difficilement. En effet, d’un point de vue géographique, le pays est très éloigné de la région. Son point le plus au Nord est situé à 1400 km des franges sud du cercle polaire. De plus, la Chine ne dispose d’aucun territoire dans la zone. Elle est néanmoins parvenue à construire son identité en Arctique en entretenant des relations multilatérales. Elles ont ainsi renforcé la perception que la Chine est un acteur majeur en matière de développement régional. Petit à petit, Pékin a inclus l’Arctique dans son grand projet des « Nouvelles routes de la soie » tout en mettant en avant ses ambitions de « Routes de la soie polaires ». Elle développe par la même occasion le concept du « proche-Arctique ».
Afin de mieux comprendre la construction de l’identité chinoise en Arctique, l’auteur examine les relations multilatérales de la diplomatie de Beijing. Il note le rôle prépondérant de la Chine au sein du Conseil de l’Arctique et rappelle qu’elle ne dispose que d’un statut d’observateur. Tout d’abord, Pékin noue des partenariats avec les gouvernements de la zone polaire. Ces liens sont les plus étroits avec la Russie en raison du projet des « Routes de la soie polaires ». De plus, la Chine créé des partenariats bilatéraux avec la Finlande et l’Islande. Au-delà de ces relations gouvernementales, elle établit des interactions avec des acteurs non-étatiques notamment scientifiques et académiques. Une délégation chinoise est systématiquement présente aux conférences des think tank internationaux «Arctic Circle», «Arctic Frontiers» et «Arctic: territoriy of dialogue». La Chine s’apprête également à dynamiser son propre think tank en la matière par le biais du Centre de Recherche chinois sur l’Arctique.
Cette affirmation identitaire de la Chine en Arctique fait naître des rivalités. L’auteur cible en particulier les interrogations de puissances occidentales telles que les États-Unis par exemple. En dépit de son statut d’observateur, la Chine s’est créé en moins d’une décennie une identité dans le cercle polaire Arctique. Celle-ci la place désormais comme un acteur prépondérant dans une zone pourtant éloignée de son territoire national.
Vous êtes-vous déjà demandé ce qu’une faute de frappe dans une feuille Excel pouvait engendrer ?
Dans cette vidéo de la chaîne ScienceEtonnante, David Louapre explique comment une erreur de calcul (dans le meilleur de cas) pourrait être à l’origine de recommandations mondiales en matière d’austérité.
Cette histoire nous permet de mettre en lumière l’importance du respect de la démarche scientifique et notamment de l’évaluation par les pairs.
Retrouvez les données ainsi que le code utilisé dans la vidéo sur cette page.

L’article évoqué ci-dessous a été publié le 2 janvier 2020 sur l’archive ouverte pluridisciplinaire HAL. Cette dernière est destinée au dépôt et à la diffusion de travaux de recherche, publiés ou non, en provenance d’établissements d’enseignement supérieur français ou étrangers mais aussi de laboratoires publics ou privés.
Ce document a été rédigé par Lydien Walter Panemi de Muishe diplômé d’un Master II en Sciences politiques, Relations Internationales et Études stratégiques de l’Université de Yaoundé au Cameroun. L’auteur se penche sur les liens qui unissent l’islam radical à l’identité religieuse au Nigeria à travers une réflexion sur les logiques identitaires et conflictuelles de Boko Haram .
L’actualité récente a démontré que Boko Haram était autant un facteur de frictions qu’un vecteur de tensions entre ethnies et communautés nigérianes, particulièrement dans la ville de Maiduguri, engendrant violences, heurts et massacres. S’appuyant sur cela, l’auteur explique comment la proclamation identitaire et la représentation de l’ennemi incarnent des logiques de radicalisation religieuse et de légitimisation de la violence pour le groupe en question. En effet, le discours identitaire et autocentré construit par le groupe présente l’organisation terroriste comme un catalyseur de pureté religieuse, légitimé par une idéologie traditionnelle et radicale. Mû par la volonté de bâtir une véritable communauté des croyants musulmans (la oumma), le groupe n’hésite pas à écarter de son projet idéologique tous ceux qui dérogent à ses préceptes : les infidèles, les mécréants, les impurs et les déviants. La doctrine ainsi suivie par Boko Haram se traduit par un traditionalisme affirmé et un rejet de plus en plus marqué de la modernité qui est perçue comme une source d’aliénation et de domination occidentale.
Cette stigmatisation du partisan et de l’adversaire a conduit l’auteur à s’interroger sur les représentations de l’ennemi chez Boko Haram. Tous ceux ne partageant pas les dogmes idéologico-religieux de ce dernier sont reprouvés dans une logique insurrectionnelle et destructrice. Lydien Walter explique que le groupe construit une dialectique entre un adversaire interne lié à la politique intérieure du pays et l’ennemi étranger caractérisé par la modernité occidentale et les déviances qui en découleraient. Au-delà de la construction du narratif idéologique, il nous est exposé que d’autres logiques identitaires sont mises en œuvre par le groupe comme par exemple la sanctuarisation de zones d’influence. C’est notamment le cas des villes de Maiduguri, Gwoza, Chibok ou encore Damatru qui ont été à plusieurs reprises le malheureux théâtre des actions de Boko Haram.
La radicalisation du fait religieux promis par Boko Haram cristallise les logiques conflictuelles interethniques et inter communautaires au Nigeria. Plus généralement, se pose ainsi la question des liens sous-jacents qui unissent identité et religion. A la dialectique de l’ami et de l’ennemi décrite dans cet article, pourraient s’ajouter les réflexions de Samuel Huntington qui affirmait : « les religions fournissent une identité en distinguant le croyant du non-croyant, le membre de la communauté de celui qui en est exclus[1]»
[1] HUNTINGTON Samuel, Le choc des civilisations, Odile Jacob, « Poch Odil Jacob », 1996, 545 pages.


Dans l’article ci-dessous datant du 27 janvier 2020, rédigé en anglais et publié sur le site behavioralscientist.org, Stephanie Tam écrivaine, chercheuse et productrice indépendante s’interroge sur l’impact de l’immigration sur l’innovation et l’entrepreneuriat aux Etats-Unis.
Les économistes savent depuis longtemps que l’innovation est une des clés de la croissance. L’auteure essaye de comprendre à quel point l’immigration contribue à l’innovation et nous explique comment les chercheurs ont utilisé les bases de données relatives aux brevets (titres de propriété industrielle) pour répondre à cette question. Ces derniers ont pu montrer que les immigrants contribuaient de façon disproportionnée à l’innovation américaine. Plusieurs raisons sont avancées dans l’article. Ainsi, la propension des immigrants à prendre plus de risque est soulignée. Ces derniers ont déjà tous pris un risque en quittant leur pays. En outre, certaines données montrent que les immigrants ont tendance à faire moins d’études que la population autochtone. En revanche, ceux qui en font se sont retrouvés en grande proportion à des niveaux très avancés (ex : Doctorat). Ils seraient aussi plus susceptibles de créer leur propre travail car leur expérience à l’étranger ne serait pas reconnue sur le sol américain. De façon générale, ils n’auraient pas les mêmes opportunités d’emploi que les américains.
Le fait de ne pas avoir été élevé dans la culture américaine leur octroierait des possibilités de penser hors du cadre culturel commun aux individus nés sur le sol américain et ainsi, leur donnerait un avantage certain en terme d’innovation. Ce sont donc des motifs culturels et motivationnels qui sont principalement avancés pour expliquer le phénomène étudié.
Les chercheurs montrent également que, loin de ne faire que s’accaparer une part de l’emploi, les immigrants contribuent très largement à la création de celui-ci.
La disproportion de la contribution des immigrants se retrouve dans plusieurs secteurs. Ainsi, pas loin de la moitié des 500 entreprises les plus riches des Etats-Unis ont été fondées par les immigrants ou leurs enfants. En outre, un peu plus de la moitié des immigrants ayant eu le prix Nobel en chimie, médecine, physique ou économie vivaient sur le sol américain lors de leurs travaux.
Enfin, il est à noter que des études récentes tendent à montrer que les Etats-Unis sont de moins en moins attractifs pour les talents étrangers au détriment d’autres pays tels que le Canada ou le Royaume-Uni. Cela serait dû au durcissement de la politique d’immigration américaine.

Dans l’article que vous trouverez en cliquant sur le lien ci-dessous, Vincent Yzerbyt et Olivier Klein expliquent en quoi le terme de distanciation sociale, utilisé lors de la crise du coronavirus, est à leurs yeux inapproprié. Ce faisant, les auteurs soulignent l’importance du lien social dans la vie quotidienne et plus particulièrement en temps de crise.